Have you ever thought of how Netflix consistently gives you personalized suggestions for movies based on your past preferences? Well, such special abilities are only possible when you apply unsupervised learning. It is a machine learning algorithm that will learn by itself by identifying patterns in the data. In this blog, we will learn the basics of unsupervised learning, the need for its existence, and its workings. We will look into techniques that help to group things based on how much they resemble each other and know the difference between supervised and unsupervised learning and observing real-world applications.
Table of Contents
Watch this concise training video on machine learning led by industry professionals.

What is Unsupervised Learning?
Unsupervised learning is a branch of machine learning where algorithms find patterns, or structures in the data without receiving results that come with labels. Let’s take an example where I have 10 pictures of apples and 10 pictures of mangos and I have names in front of each image. This type of data is called labeled data. If only images are given and no names are mentioned then that type of data is referred to as unlabelled data.
Common techniques in unsupervised learning include clustering algorithms like K-means or hierarchical clustering, as well as dimensionality reduction methods like principal component analysis (PCA). Its primary goal is to discover hidden or in-built structures within the dataset, such as grouping data that are similar to each other(clustering) or reducing the attributes or columns of the data while preserving its meaningful information (dimensionality reduction).
Transform your knowledge in the domain with our machine learning course – Enroll now!
Why Do We Need Unsupervised Learning?
Unsupervised learning methods are essential in various fields like anomaly detection, assisting in data exploration, feature extraction, and understanding complex systems. Let’s discuss these methods in detail:
- Exploratory Data Analysis: Unsupervised learning helps in exploring and understanding the structure of data when categories are unknown or not well-defined.
- Dimensionality Reduction: Unsupervised learning methods, such as Principal Component Analysis (PCA) or t-distributed Stochastic Neighbor Embedding (t-SNE), are used to reduce the dimensionality of data. This helps in visualizing high-dimensional data and can lead to more efficient and effective feature representations.
- Feature Learning: It can automatically discover relevant features from data without external guidance. This is particularly useful when dealing with high-dimensional and complex datasets, where identifying meaningful features can be challenging.
- Anomaly Detection: Unsupervised learning models can identify irregularities in data by learning the normal patterns. This is valuable in various applications, including fraud detection, network security, and quality control.
How Does Unsupervised Learning Work?
One common technique is clustering, where the algorithm groups similar data points together based on certain features or similarities.
Let’s consider an example where we have a collection of various fruits without any labels or categories. Using unsupervised learning, you can group these fruits based on similarities, such as their shape, color, or size, without being told what each fruit is. The algorithm forms clusters where,
- Fruits with similar characteristics like round shape and red color might be grouped together, forming a cluster representing apples.
- Fruits with similar characteristics which are elongated with yellow can be considered as papaya forming another cluster.
- Fruits with similar characteristics like purple color, small size, and oval shape (representing berries) are grouped forming another cluster.
Without clear labels, the computer program can identify groups on its own as we saw above. It does this by finding similarities in the data, even if we haven’t mentioned specifically what to look for. This is what unsupervised learning is all about—sorting and arranging information without having specific categories or instructions beforehand.
The following are the Top 50 Machine Learning Interview Questions and Answers to help you ace your interview.
Types of Unsupervised Learning
There are three different types of unsupervised learning:
- Clustering
- Association Rules
- Dimensionality Reduction

Clustering
Clustering is a technique used to group similar items or data points together based on certain characteristics or features. Clustering can help to identify data points that are far away from the dataset (outliers) or variations in a dataset.
For example, in customer segmentation for a retail business, clustering can be employed to group customers based on their purchasing behavior. Imagine a dataset containing various customer attributes like age, spending habits, and product preferences. By applying clustering algorithms like K-means or hierarchical clustering, similar customer profiles can be grouped together. This can result in clusters representing, say, budget-conscious buyers, luxury shoppers, and occasional purchasers.
K Means Clustering
K Means Clustering is a division method used in data analysis and machine learning, where data points are grouped into K clusters based on their similarity. The objective is to minimize the within-cluster sum of squares, meaning that the data points within each cluster are as close to each other as possible.
Hierarchical Clustering
Hierarchical Clustering is a method of clustering analysis that aims to build a hierarchy(tree) of clusters. It creates a tree of clusters known as a dendrogram, where each data point starts as its cluster, and pairs of clusters are then merged or divided based on their similarity.
Association Rules
Association Rules in unsupervised machine learning are patterns discovered in datasets to check if there is any correlation between variables. They identify connections among items, revealing frequently occurring combinations, often used in market basket analysis or recommendation systems to understand item associations.
Apriori Algorithm
The Apriori Algorithm is a classical algorithm in data mining used to find common groups of items in a dataset and generate association rules based on these common groups.
The algorithm’s efficiency lies in reducing the search space by eliminating item sets that do not meet the minimum support benchmark, making it feasible to mine frequent item sets efficiently in large datasets.
Dimensionality Reduction
Dimensionality reduction in unsupervised machine learning refers to the process of reducing the number of features or variables in a dataset while keeping its meaningful information. It aims to simplify complex data by transforming it into a lower-dimensional space, assisting in visualization, computational efficiency, and noise reduction without explicit target labels.
Principal Component Analysis
Principal Component Analysis is a dimensionality reduction technique used to simplify complex datasets by transforming variables into a new set of uncorrelated variables called principal components. It aims to capture the data with fewer dimensions while retaining as much of its variability as possible.
Want to know more about types of machine learning? Read our blog on Reinforcement Learning, one of the types!
Practical Implementation of Unsupervised Learning
Choosing the right unsupervised learning algorithm is essential for uncovering meaningful patterns and structures within unlabelled data
Given below is a simple example code for one of the unsupervised learning techniques. Let’s use the K-Means clustering algorithm as an example. For this, we’ll use the popular Python library scikit-learn. Make sure you have it installed using “pip install scikit-learn”
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# Generate synthetic data
data, _ = make_blobs(n_samples=300, centers=4, random_state=42)
# Apply K-Means clustering
kmeans = KMeans(n_clusters=4)
kmeans.fit(data)
labels = kmeans.labels_
centers = kmeans.cluster_centers_
# Visualize the clustered data
plt.scatter(data[:, 0], data[:, 1], c=labels, cmap='viridis', edgecolors="k", s=50)
plt.scatter(centers[:, 0], centers[:, 1], c="red", marker="X", s=200, label="Cluster Centers")
plt.title('K-Means Clustering')
plt.legend()
plt.show()
Output:
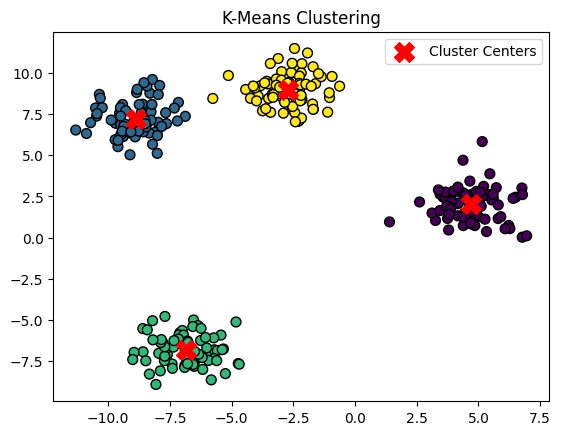
In this example:
- This Python code generates synthetic data with four clusters using the make_blobs function from sklearn.datasets.
- It then applies the K-Means clustering algorithm to the data with the specified number of clusters (k=4).
- The resulting cluster labels and centroids are obtained.
- The code visualizes the clustered data points using a scatter plot, where each cluster is assigned a different color.
- Additionally, it marks the cluster centers with red X markers.
- The plot provides a clear representation of how K-Means has grouped the data into four clusters, showing the effectiveness of the clustering process.
- The matplotlib.pyplot library is utilized for creating the visual representation.
- In the output image, there are four clusters (green, blue, yellow, and purple). Each cluster has similar properties, but they are different from each other, respectively.
Difference between Supervised and Unsupervised Learning
The following table illustrates Supervised Learning vs Unsupervised Learning. The differences capture the contrasting nature of supervised learning, which relies on labeled data for prediction, and unsupervised learning, which explores patterns and structures within data lacking explicit labels.
| Key Point | Supervised Learning | Unsupervised Learning |
| Target | Labeled data (Input and Output) | Unlabeled data (Only Input) |
| Objective | Predict or classify based on labeled data | Discover patterns, structures, similarities or relationships |
| Learning Approach | Guided learning | Self-organizing learning |
| Example | Regression, Classification, Object Detection | Clustering, Dimensionality Reduction, Association |
| Feedback | Feedback is provided during training | No feedback or target is provided during the training |
| Evaluation | Accuracy, Precision, Recall | Silhouette score, Inertia, Explained Variance |
| Usage | Well-defined problems with known outcomes | Exploration, Pattern recognition in data |
Applications of Unsupervised Learning
Unsupervised machine learning has various applications across different domains. Some key applications include:
- Association Mining: Discovers relationships between products bought together for retail strategy. Market basket analysis is one of the examples.
- Recommendation Systems: Provides personalized content or product recommendations based on user preferences.
- Data Synthesis: Creates artificial datasets with similar properties to real-world data for model testing and privacy preservation.
- Text Mining: Uncovers latent topics in large text collections for information retrieval and content organization.
- Biological Data Analysis: Identifies patterns in biological data, such as gene expression or protein interactions.
- Healthcare Analytics: Analyze health data to categorize patients for personalized treatment plans or diagnostics.
- Network Analysis: Identifies groups or communities within networks for a better understanding of relationships.
Concluding Thoughts
Unsupervised learning, with its ability to reveal hidden patterns in unlabeled data, holds immense promise. Its future lies in driving innovations across diverse domains such as image processing, finance, and AI-generated content creation. As technology advances, unsupervised learning will play an important role in solving complex data, enabling more accurate predictions, personalized experiences, and groundbreaking discoveries, promoting a future where insights are derived even from the most complex datasets without the need for labeled information.
FAQs
What is unsupervised learning?
Unsupervised learning is a type of machine learning in which the algorithm works with unlabeled data, aiming to uncover patterns, relationships, or structures within the data without relying on explicit guidance or labeled examples.
What is clustering?
Clustering is a type of unsupervised learning where the goal is to group similar data points based on certain criteria. Common clustering algorithms include K-means, hierarchical clustering, and DBSCAN.
Can you provide an example of a real-world application of clustering?
One real-world application of clustering is customer segmentation in marketing. By clustering customers based on their purchasing behavior, businesses can make marketing strategies for specific customer segments, improving overall targeting and satisfaction.
What is dimensionality reduction?
Dimensionality reduction is a technique used in unsupervised learning to reduce the number of features (or dimensions) in a dataset while retaining its essential information. Principal Component Analysis (PCA) is a commonly used dimensionality reduction technique.
What are some challenges in unsupervised learning?
Challenges in unsupervised learning include the absence of labeled data for training, the subjective nature of evaluating results, and the difficulty in choosing appropriate parameters for algorithms like clustering or dimensionality reduction.
How does unsupervised learning differ from supervised learning?
In supervised learning, the algorithm is trained on labeled data with input-output pairs. In unsupervised learning, the algorithm works with unlabeled data and aims to discover inherent patterns or structures without explicit guidance.