Generative AI has been a booming sector since the introduction of ChatGPT. Different sectors have widely adopted it, including media, marketing, supply chain, investment banking, software development, HR, operations, and sales.
According to The State of AI, a report by McKinsey and Company, organisations have seen a meaningful cost reduction and an increase in revenue by introducing generative AI. According to Statista, the market size for generative AI is USD 184 billion in 2024 and is expected to grow exponentially.
As organisations adopt Artificial Intelligence, there is a huge demand for AI Engineers and Consultants. According to LinkedIn, there are 7000+ GenAI job openings in Bengaluru and 134000+ worldwide. GenAI professionals are paid very well. Someone starting can get a pay ranging between INR 8LPA and 43LPA. Product-based companies, especially startups, pay GenAI professionals an average of INR 30LPA—INR 40LPA.
So here are a few questions curated by experts to ace your upcoming generative AI interviews. These Gen AI interview questions are segregated under the following headings:
Generative AI Interview Questions for Freshers
1. What is the fundamental difference between discriminative and generative models in machine learning?
Discriminative machine learning models usually focus on differentiating between classes. The goal is to predict the label of the data point given its feature.
Imagine you are classifying between humans and dogs. A discriminative model will look for features in the image such as “this pixel looks like a feather” or “this image contains four legs” and then use the same information to predict either dogs or humans.
Generative machine learning models not only focus on differentiating between classes but also on how these are generated.
Taking the same example of classifying dogs and humans, a generative model will look for features and how they are generated, such as pixel patterns, textures, etc., and learn how to create an image of a dog or a human.
2. What is the key difference between correlation and causation?
Correlation implies a relationship or association between two variables such that one changes at the same time as the other. In a correlation, the cause is not necessarily implied.
For Example, Ice cream sales and sunburns increase together during summer. Although ice cream sales and sunburns are unrelated, this is a correlation.
Causation occurs when one variable directly affects the change of another variable.
Again taking the same example, Ice cream sales and sunburns increase together during summer. The two share a seasonal association. You buy an ice cream because it’s sunny, or you get sunburned because it’s sunny. This is known as causation, where the event has a cause to which it can be related.

3. What is the significance of tokenisation in LLM processing?
In LLM, tokenisation is the process of text segmentation, where a text is segmented into tokens, which could be words or subwords. Applying this means that the model can easily analyse and interpret the content in these texts whenever needed for training and inference by converting these texts into numerical forms.
For example, the input word string “A dog has four legs” is tokenised. The given string is split to form the following array: [‘A’, ‘dog’, ‘have’, ‘four’, ‘legs’]. This helps the model examine the definition of each word individually and more effectively.
4. What is Narrow AI? Mention a few of its typical applications.
Narrow AI, or weak AI, is a type of AI created to perform specific tasks within a specified domain, unlike human intelligence, which can be applied to a broader domain. Virtual assistants like Siri and Alexa are the most popular applications. Other popular applications include spam filters, recommendation systems, and image recognition.

5. Explain how natural language processing (NLP) works.
NLP or Natural Language Processing combines language analysis and artificial intelligence that helps computers understand human language.
Models use particular transformations, such as tokenisation and parsing, and vary depending on their intended use, which may include translation and summarisation.
For instance, if the user speaks to Siri, NLP translates the user’s speech to text, recognises against the named entities (NER), comprehends the intent and context from embedding words, gathers what is required, and produces a response.
Generative AI Interview Questions for Intermediate
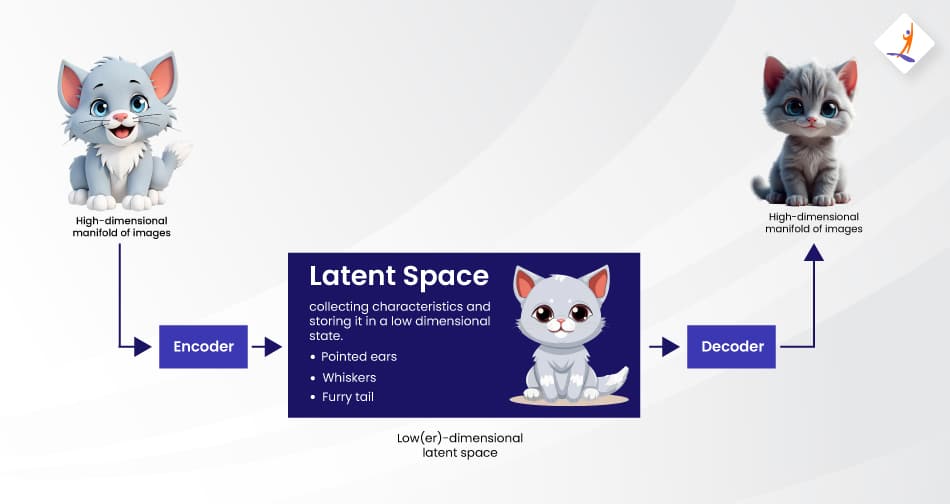
6. What exactly does Latent Space mean in the context of VAEs?
In Variational Autoencoders (VAEs), the term “latent space” describes a condensed version of the input information, with dimensions compared to the dataset size. It is a lower-dimensional, continuous space for storing useful and compact representations or features of the data.
Let’s take an example to understand it. Imagine we have a high-dimensional image of a cat, as shown in the image below.
- Encoder: It transforms the cat’s high-dimensional input into lower-dimensional latent space and then represents it as a distribution, mean, and variance.
- Latent Space: A continuous, lower-dimensional space where comparable data points are clustered to capture significant traits and changes such as pointed ears, furry tails, etc.
- Decoder: It takes latent space samples and reconstructs them into high-dimensional data.
7. What is Mode Collapse in GANs?
Mode collapse in Generative adversarial networks(GANs) occurs when the generator can only generate a few modes or repeat the same modes without generating all the required diversification of the target data distribution. Instead of generating a broad array of samples, the generator may work only with a limited set of outputs, which means no variation.
Let’s consider that you are training a GenAI artist to paint cats, dogs, cows, etc. It comprises – a Generator, which generates the image and a Discriminator, which assesses the image. For instance, the GenAI can draw a dog, and after some practice, the discriminator says, “Wow, it looks real”. The GenAI becomes lazy as it understands a way to fool the discriminator. Whenever you ask it to draw some animal, it draws a dog, and the discriminator says, “Wow, that looks real”. It doesn’t try to draw anything else other than a dog. This situation is called mode collapse in GANs.
8. Why is training GANs a challenge?
The complicated interaction between the generator and discriminator makes it challenging to train GANs. It can be treated as a min-max game because the generator tries to fool the discriminator by creating almost real data. In contrast, the discriminator strengthens its ability to distinguish between real and generated data. It is rather complicated to find some kind of balance by which improvement is mutually possible for both of the networks and for that reason, the mentioned problems might occur:
- Mode Collapse: Here, the generator produces the same few outputs and does not represent the data distribution in the overall process. The approach may not be stable, in which case losses are very irregular, and little convergence is observed.
- Vanishing gradients: If the discriminator is too powerful, it might send less information to the generator, and gradients will vanish, leaving the generator’s learning in limbo.
- Hyperparameters are sensitive to instability: GANs must carefully fine-tune them, such as learning rate and batch size, to ensure a stable training environment.
These are a few reasons why training GANs are challenging.
9. What is hallucination, and how can it be managed with Prompt Engineering?
This is the case when an AI language model generates data that reasonably looks realistic but is not real. It is thus wrong or even completely fake beyond those overextensions from the training data sets or misguided explanations of input data.
For instance, if you ‘talk’ to an AI exponent, you can ask, “Who addressed at the 1802 United Nations Summit?” It would create a false answer even though no such summit took place.
Prompt engineering enhances control over hallucination by making precise and contextually rich prompts that better guide the model. The specificity and directness of questions and the explicit context in which a question is asked reduce uncertainty and the chances of producing incorrect information. Techniques such as inserting limitations, examples, or instructions into prompts can increase the dependability and correctness of generated responses.
10. How do you determine the quality of generated samples from a generative model?
The quality of samples produced by a generative model is checked in the following way:
- In qualitative assessment, a model will apply aesthetic impression, or at times, human intuition, to verify such realism and unsophisticated variability.
- Quantitative metrics:
- Inception Score (IS): A pre-trained classifier measures the quality and diversity of the automatically generated images.
- Fréchet Inception Distance (FID): The similarity of the distributions between generated and real data; lower is better.
- Precision and Recall: These measures estimate the realism, precision, diversity, or variety of the generated results or recall.
- User Studies: Gather user responses on a system’s performance to ensure coherence and relevance.
- Perceptual Metrics: Measure the text or audio using appropriate metrics, such as BLEU, ROUGE, or MOS, to score it compared to references.
Generative AI Interview Questions for Experienced
11. How can a person manage computational efficiency and scalability when working with large-scale generative models?
To cope with the scalability and computing efficiency of large-scale generative models, various ways can be used:
- Model optimisation: To address the problem of lowering the complexity of the model while at the same time compromising on the performance, techniques such as quantisation, model pruning, and knowledge distillation do work.
- Distributed Training: To speed up training, use systems of multiple GPUs or even TPUs to parallelise the computation and balance the load over many devices.
- Efficient Architectures: Architectures that scale better than traditional architectures in current practice include variants of transformers or sparse attention models that can dramatically reduce computing requirements.
- Batching and mixed precision: To optimise computation and memory, you can use larger batch sizes and specified mixed precision, including Fp16.
12. What does KL Divergence mean when used in VAEs, and why is it useful when training generative models?
The KL Divergence, or Kullback-Leibler Divergence, measures the difference between a learned latent distribution and a given prior distribution, primarily a standard normal distribution. It then minimises KL Divergence such that the learned latent space becomes close to this prior; samples are coherent and diverse while still sampled from this learned distribution.
For example, in the image generation task, KL Divergence makes the latent space have interesting patterns so that VAE can generate realistic-looking images while learning to generate new samples. This is especially true in applications such as synthetic faces or pictures, where each sample should be unique yet belong to similar classes of images.
That is why the balance of the reconstruction function and the regularisation makes KL Divergence more valuable for VAEs in generative tasks, image synthesis, and speech generation, among other tasks.
13. What are Energy-Based Models (EBMs), and how do they differ from generator models such as GANs and VAEs?
- Energy-based models (EBMs) quantify energy for different variable configurations, assuming that the data will take low-energy and high-energy states will be rare.
- The analysis of EBMs does not require a specific representation of the probability distributions. However, they sort configurations in terms of energy to maintain the characteristics of a data structure.
- This means that unlike GANs, EBMs lack discriminative capability, perhaps partially or in full, depending on the model used. This differs from defining an energy function without adversarial training, while they aim right at assigning energy levels.
- While in VAEs, the probability distribution over the latent space is defined directly, in EBMs, data likelihood is defined implicitly with the idea that the samples having smaller energy values are more likely.
- Use Case: EBMs are useful in complex situations where precisely describing probability distributions is difficult.
14. How do diffusion models like Denoising Diffusion Probabilistic Models (DDPMs) work, and what makes them competitive in generative tasks?
Denoising Diffusion Probabilistic Models (DDPMs) transform noise into structured samples by a process of denoising. This process produces and transforms raw noise into pure noise while delivering coherent data in the form of pictures after a certain number of rounds.
- Process: DDPMs progressively add noise to data (forward process) and learn to denoise and restore it.
- Competitive Advantage: They produce high-quality, stable, and diverse samples without the mode collapse suffered in GANs, making them suitable for high-fidelity jobs such as picture and audio synthesis.

15. How do you implement a text-to-image synthesis model?
Follow the below steps to implement text to image synthesis model:
- Gather ample image data along with detailed captions to correspond with them.
- Model selection: Select a GAN or Diffusion Model paired with a text encoder like CLIP or Transformers trained to map text descriptions into images’ latent space and generate authentic images that adhere to textual resolutions.
- Learn to decode word descriptions into image latent spaces and to produce images and other visuals from text input.
- Generation: Given a new text, create sample imagery based on the learnt distribution over the latent space.
Among these architectures, AttnGAN, StackGAN, and DALL-E are widely used. Such models learn the relationship between visual and linguistic properties and can produce high-quality images from detailed textual descriptions.
16. What is the concept of attention in generative models?
The attention concept applied in generative models makes the model concentrate on a certain part of the input while enhancing its response. It can put more weight on a certain part of input than on others. That is especially beneficial in models such as Transformers (GPT, BERT) for machines associated with machine translation and text-image generation tasks since it helps the model manage complicated dependencies and produce high-quality outcomes.
For instance, in text-image synthesis where a description such as ‘‘a red car on a sunny beach’’, attention helps the model to pay its focus on words such as ‘‘red car’’ and ‘‘sunny beach’’, and their contribution is appropriately reflected in the synthesised image. In other words, this particular weighting helps explain the outcome and makes sense of the output.
17. How do you ensure your AI models are ethical and unbiased?
The following must be done for the AI models developed to be ethical and unbiased.
- To get different data: The training data set is not biased on negative stereotypes as it includes various opinions and communities. Thus, it is recommended to introduce balanced datasets with different populations, cultures, and situations.
- Bias Detection and Mitigation compare models with their regular predictions based on gender, race, or socioeconomic status bias. Tools and methodologies such as fair constraints and adversarial debiasing may reduce biases caused by training.
- Explainability and transparency: The explanation methods that implement the explanation strategies must assist stakeholders in understanding how an AI model concludes. If performed by AI, it will look for any ethical issues that may be present and provide an audit trail of decision-making if necessary.
- The monitoring phase is a continuous process consisting of periodic reviews. It deploys monitoring tools designed to prevent models from having harm or biases against people from certain groups unintentionally.
- Adherence to ethical standards and best practices taken from renowned institutions in ethical advice. Examples include IEEE, OECD, and AI Now Institute, as their studies now embrace justice and transparency about AI for more accountability.
18. What is Q-Learning?
Q-learning is another model-free reinforcement learning in which the presented algorithm decides what action should be taken at the current state by considering rewarding values. It works by having a Q-table, which contains Q-values for every potential combination of state and action the algorithm envisions to give a prediction of future rewards.
According to the Bellman equation, the agent iteratively updates these variables as it interacts with its environment. Q-learning enables an agent to discover the best way to accumulate maximum cumulative rewards over time through exploration and exploitation.
19. How do you implement and tune the loss functions for generative models, and why is this important?
Implementing and tuning loss functions for generative models guarantees effective learning and achieving high-quality results.
- For GANs, Loss is often a min-max game played between the generator and discriminator. The model optimises via binary cross-entropy or hinge loss.
- For VANs: The actual loss function in a VAE is a tradeoff between reconstruction loss, such as mean squared error and KL divergence, which govern the latent space and generate realistic samples.
- For Diffusion Models, the loss is determined by denoising score matching. By minimising the difference between predicted and actual noise in the data, the model learns to reverse a diffusion process.
It means adapting the parts (in the case of VAEs, reconstruction and KL divergence terms), appropriately adjusting the learning rates, and proper weighting to avoid mode collapse in GANs or poor latent space representation in VAEs.
A well-tuned loss function pushes a model toward efficient convergence with a good quality of diversified outputs.
20. How do you evaluate the performance of a generative model, and what metrics are commonly used?
The quality of a generative model is determined in terms of the sample generated, which should be realistic, diverse and of high quality. The metrics used to evaluate generative models usually vary and depend on the goal and type of model:
- Inception score: Diversity and clarity of generated images are both measured by IS.
- Fréchet Inception Distance (FID) compares the feature distribution among generated and authentic images. The lower the FID, the better the performance.
- Mean Squared Error (MSE): It measures pixel-level gaps. This is extensively used for image reconstruction.
- Perceptual Similarity: Using pre-trained networks, it measures how perceptually similar generated images are to real ones.
- Diversity Metrics: Measures how dissimilar the generated outputs are to the data distribution.
- Visual Turing Test: Subjective Human Evaluation of whether the produced data seems realistic.
Conclusion
We hope this article helps you gain knowledge to ace your following generative AI interviews. Generative AI is a booming field and has grown exponentially over the years. The industry demands more seasoned generative AI engineers to fill the gap.
If you want to learn Gen AI systematically from top faculty and industry experts, you can enroll in our Generative AI Course with placements.