There are various algorithms in Machine learning for classification and regression tasks. One of the simplest algorithms is K-Nearest Neighbors (KNN). It is a non-parametric, supervised learning algorithm. It helps to classify new data points, which are based on the similarity with existing data. It works by identifying the ‘k’ nearest points (neighbors) to a given input. It then predicts its class or value based on the majority class or the average of its neighbors.
In this blog, we will explore the concept of the KNN algorithm and demonstrate its implementation using Python. So ,let’s get started!
Table of Contents
What is K-Nearest Neighbors (KNN)?
KNN is a simple instance-based learning algorithm. It is used for classification and regression tasks. The algorithm works by finding the closest data points (neighbors) in the dataset. It then makes predictions based on the majority class (for classification) or the average value (for regression).
For example, if we want to classify a fruit as an orange, KNN will look for the first K nearest fruits in the dataset. If most of these are oranges, then it will classify the new fruit as an orange.
How Does KNN Work?
The working of KNN is a straightforward process.
- Choose K (number of neighbors).
- It then measures the distancebetween the new data point and all the existing data points present in the dataset.
- It then selects the K closest points.
- Lastly, it makes a prediction based on the majority class or the average value.
Example:
If we take K=3, and the three closest points are 2 apples and 1 orange, the new data point is classified as an apple.
Choosing the Right Value of K
The value of K plays an important role in the performance of KNN.
- Small K (e.g., K=1, K=3):
Taking a small value of K makes the model highly sensitive to noise. This can also lead to overfitting. It also captures local patterns but may misclassify due to the presence of outliers.
- Large K (e.g., K=10, K=20)
Taking a large value of K smoothens the results and reduces noise. It also can lead to underfitting. It also makes the model to ignore important details.
The best way to choose the value of K is to have a common thumb rule, like set the value of K = √(total number of data points). You can also experiment with different K values and validate the model performance using cross-validation.
Implementation of KNN in Python
Here, we will be using the Iris dataset to demonstrate KNN for classification.
Step 1: Importing Libraries and Loading Dataset
Example:
Output:

Explanation:
The above code is used to load the Iris dataset. It splits it into training (80%) and testing (20%) sets, and then prints the success message at last.
Step 2: Training the KNN Model
Example:
Output:

Explanation:
The above code is used to initialize a K-Nearest Neighbors (KNN) classifier. It takes the value of K as 3, and then trains it using the training data. At last, it prints a success message.
Step 3: Making Predictions
Example:
Output:

Explanation:
The above uses the trained KNN model which helps to predict labels for the test dataset. It then prints the predicted class labels.
Step 4: Evaluating the Model
Example:
Output:

Explanation:
The above code is used to calculate the accuracy of the KNN model. It compares the predicted labels (y_pred) with actual labels (y_test) and then prints the accuracy score.
Step 5: Finding the Best K Value
Example:
Output:
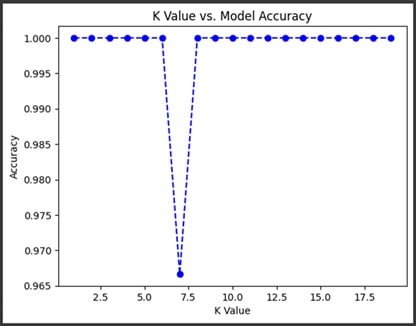
Explanation:
The above code is used to evaluate the KNN model’s accuracy for different values of K (from 1 to 19). It then stores the accuracy scores and then plots a graph which helps to visualize the relationship between K and the accuracy of the model.
Limitations of KNN Algorithm
Some of the limitations of the KNN algorithm are given below:
- Simple but lacks internal learning: KNN doesn’t depend on internal machine learning models for predictions. Instead, it classifies based on the existing data points.
- It cannot predict Rare Events: KNN finds it hard to identify unusual events. For example, new diseases. Since it does not have prior knowledge of rare data distributions, it struggles to identify the new diseases.
- It is computationally Expensive: KNN requires significant time and memory to store the entire dataset. It then performs distance calculations for each prediction.
- It is Sensitive to Feature Magnitudes: In KNN, features which have larger magnitudes dominate the ones with smaller values. This is due to Euclidean distance metric, which leads to biased predictions.
- It is not Suitable for High-Dimensional Data: With large-dimensional datasets, KNN becomes inefficient due to the “curse of dimensionality”. This makes it less effective as the number of features increases.
Best Practices for Using the KNN Algorithm
Some of the best practices to enhance the performance of the K-nearest neighbors (KNN) algorithm are given below:
- Choose the Optimal Value of K: Selecting an appropriate value of K is important because a small K (e.g., 1 or 3) can lead to overfitting, while a large K (e.g., 10 or 20) may cause underfitting. This can be done by setting K as the square root of the total number of data points.
- Normalize Features: Since KNN uses distance-based calculations, normalizing the dataset or standardizing it ensures that features that have large magnitudes don’t dominate the results.
- Use an Efficient Distance Metric: Although Euclidean distance is commonly used, other metrics like Manhattan or Minkowski distance perform better depending on the nature of the dataset.
- Handle Class Imbalance: If your dataset has imbalanced classes, you should use weighted KNN, where closer neighbors have more influence on the classification.
- Optimize Computational Performance: For large datasets, KNN can be slow. The use of KD-trees or Ball trees for faster search of nearest neighbors can help improve the performance significantly.
- Use Cross-Validation: You can use cross-validation instead of relying on a single train-test split, which helps to determine the best K value and also avoid overfitting.
Conclusion
KNN (K-Nearest Neighbors) is a simple yet powerful algorithm, which is widely used for classification and regression tasks. It is easy to understand, non-parametric in nature, and it has the ability to adapt to different types of datasets. This makes it a valuable tool in machine learning. However, KNN also has its limitations. Some of the limitations include high computational cost and sensitivity to feature scaling and dimensionality. By normalizing data, carefully selecting the optimal value of K, choosing an appropriate distance metric, and by using dimensionality reduction techniques, you can improve the efficiency and accuracy of your model. Although KNN is not suitable for large datasets, it is always a great choice for smaller datasets where the priorities are interpretability and simplicity.
FAQs
1. What are K-Nearest Neighbors used for?
KNN is used for classification and regression tasks. This includes handwriting recognition, recommendation systems, and medical diagnosis.
2. How do I choose the best value of K?
You can choose the best value of K through experimentation. A good starting point is √(total number of data points).
3. What is the time complexity of KNN?
The time complexity of KNN for searching nearest neighbors is O(n), which makes it slow for large datasets.
4. What are the distance metrics used in KNN?
The distance metric used in KNN is Euclidean distance. Other metrics include Manhattan, Minkowski, and Cosine Similarity.
5. Does KNN require training?
No, KNN does not require training. It does not have a training phase like other models. It simply memorizes the dataset and then classifies the new points which are based on the nearest neighbors.